In the past I have complained about chronic socket exceptions on Microsoft private endpoints (PE’s and MPE’s). You can find a Christmas story about that here for example.
Of course, these anecdotes from a single Synapse customer aren’t always convincing . Others might thing I’m exaggerating the problem or spinning it to suit my purposes. It is better if these experiences can be corroborated by Microsoft themselves. Fortunately many of my experiences can be corroborated. The chronic socket exceptions that impact my custom code are also impacting the Microsoft platform itself, and causing problems in Microsoft’s own components. Just as I have struggled, they have struggled as well. Admittedly Microsoft has more engineering resources to dedicate to the problem, and they can create wrapper blocks to retry any remote TCP client connections. This works to a degree, until the network becomes so unstable that the workarounds stop working as well.
About once a month we are having blackouts in Synapse, and some of them are even sent to our service health portal. But more frequently we have “brownouts” where the percentage of jobs that are failing because of the network will exceed 25%. These incidents can be just as problematic as the blackouts, if not more. The difference is that Microsoft has a minor amount of sympathy for the impact of their “blackouts”, while they have none at all for the “brownouts”.
Below I am sharing only the “blackouts”, where Microsoft confirms that their platform was down. (Getting them to confirm this is a painful process in and of itself, so each time I get a notification in the service health portal, it is a sort of minor victory.) I don’t have much trust in Microsoft’s service health communication, especially when I have to pull teeth to get it from them, and when they start contradicting themselves or they fail to deliver a PIR. Because of this lack of trust, you will see that I often have my own interpretation of an outage that differs slightly from the Microsoft communication. However what is important to see is that Microsoft is at least confirming these recurring outages that are breaking my workloads in ADF/Synapse.
What do all the following outages have in common?
- They all resulted in the exact same symptoms within ADF/Synapse. What few error messages are exposed to ADF/Synapse users will be socket exceptions (connection timeouts, and connection resets).
- Another thing to note about these “blackouts” that are confirmed by Microsoft is that they typically coincide with a longer period of “brownout” where the network will start working again but only to a limited degree – ie. the rate of socket exceptions is high enough to cause failures in 25% percent of jobs or more.
- Remember that you may not have received the same outages, even if you are a Synapse customer in East US. These network problems are software-related, and they are rooted in bugs that exist in private endpoints (ie. proxy components). They will impact workspaces hosted in “managed vnet”, but not the ones hosted using a more conventional network technology on public internet ports.
- While the outages may be reported by the ADF team, they often impact both Synapse and ADF, since the two teams have a partnership in providing the Synapse workspace environment. They both share the same buggy network implementation. The main difference is that the ADF team has a longer history of monitoring for these VNET bugs (for the sake of their VNET IR) and are more proactive about sending outage notifications to customers than is the Spark team in Synapse.
September Outage Example
2023 September 15
Outage Tracking ID 7V95-5SZ
Microsoft explanation – Transient problems with authentication to identity provider.
More likely this is another connectivity problem related to buggy networking. (The symptoms in ADF/Synapse were no different than all my other blackouts and brownouts)

October Outage Example
2023 October 11
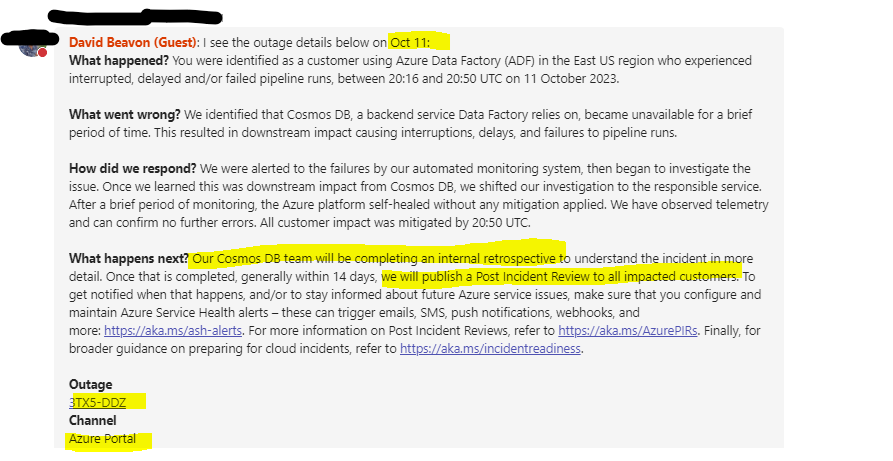
Outage Tracking ID 3TX5-DDZ
Microsoft explanation – Extensive outage blamed on cosmos.
More likely a client-side connectivity problem related to buggy networking. (Spoke with cosmos support team at CSS/mindtree and they gave a different story than the Synapse/ADF PG. They said a thirty minute outage on the cosmos side was a totally implausible scenario. Also, please note that the PIR which was promised for this outage was never delivered by the Synapse/ADF team, indicating that their preliminary RCA was probably disproven/disavowed. The cosmos PG team at Microsoft never supported the story that was being told by the Synapse/ADF PG )
November Outage Example
2023 November
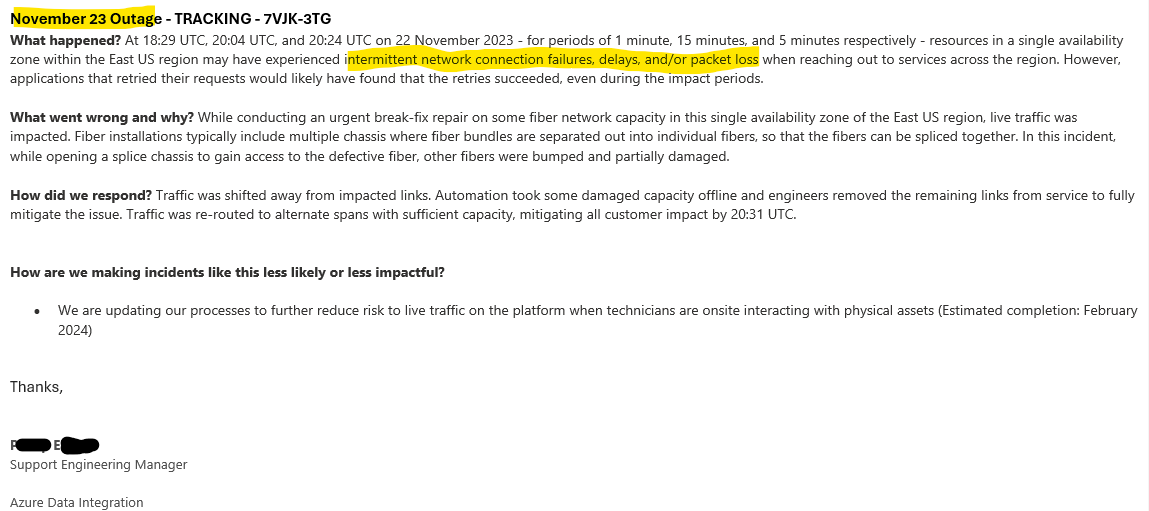
Outage Tracking ID 7VJK-3TG
Microsoft explanation – East US region may have experienced intermittent network connection failures.
More likely this is another connectivity problem related to buggy networking. (The symptoms in ADF/Synapse were no different than all my other blackouts and brownouts)
Summary
I want to address skepticism. I myself am a very stubborn and skeptical person, and usually not one to believe conspiracies theories, let alone spread them.You should be asking yourself why do these never show up on the azure outage pages (here)? Why do they only get sent to the service health for a particular tenant? Why don’t these problems have a higher level of visibility in the Synapse community?
There are many reasons. Primarily it is because it is up to the customers themselves to chase down CSS support and ask them to publish the service-health outages to our tenant dashboards whenever we have an obvious outage. That level of effort is enough to “weed out” the vast majority of customers who would otherwise be proactively notified of the problems in their environment. Even after going to the work of contacting them, Microsoft/CSS will take about a month to investigate the outage, and at the end they will say it is no longer possible to send the notification anymore to the customer’s service health portal because the impact window has passed and the communication window has been “closed”.
Another reason these Synapse problems aren’t well-documented in the public is because they are related to SOFTWARE-based networking. It isn’t a widespread problem with PHYSICAL infrastructure. It is a problem with SDN (software-defined-networking) on a particular SaaS platform, data center, physical host, virtual machine, and virtualization container. There are more than one factor in play, whenever we encounter occurrences of these network bugs. While multiple customers will be impacted every time, it is typically just a small number of them (eg. possibly based on factors like the size of workloads that are running in the multi-tenant containers of a certain VM). I don’t think the problems happen if your workload is hosted in the “Canary Region” rather than “East US”, and you are the only person who is actively using Synapse on a given day in that region, because you will be on your own host/vm/container.
Yet another reason these problem aren’t well-documented in the public is because they can be “transient”. Microsoft likes to use the phrase “transient communication failures”. They use this phrase very freely, as a way to refer to both blackouts or brownouts – ones that last any amount of time (whether just 5 minutes or a whole hour).
Every time Microsoft uses the word “transient” they are giving themselves a “free pass” on these VNET bugs with private endpoints. In the vast majority of my Synapse networking troubles, I don’t get any sympathy or support from Microsoft because they sprinkle the word “transient” (like pixie dust) into every discussion.
… that may work for a while but even Microsoft must realize that it will lose credibility after a time, especially when they start putting it into all their blackout/outage notifications as well:
- “7V95-5SZ” : “transient errors” fixed by “retry logic”
- “3TX5-DDZ” : “self-healed” after “brief period of time”.
- “7VJK-3TG” : “intermittent network failures” where applications that “retried their requests” would succeed
I’m very exhausted by networking failures in ADF and Synapse. I think these problems are well-known by Microsoft, but they deliberately impede every support case by their lack of transparency and their equivocation.
There is no way to side-step the network bugs. Using the words “transient” and “retry” in every conversation about the buggy network won’t make the problems any less severe. Nor will it actually help to avoid any of these blackouts or brownouts. I have opened well over a dozen cases about the chronic socket exceptions across multiple Azure products (Power BI, ADF, and Synapse). Almost every single support case has been a nightmare. I’m starting to believe that Microsoft’s fundamental values do NOT seem to include honesty or transparency, nor providing good customer service. More to follow.