Some Spark platforms will hide the Yarn cluster management from an application developer. The intention is good, and the idea is to make things “easy”. The actual outcome can be very bad, however, if problems are happening that are outside your control and outside your visibility.
There are a large number of platforms that repackage Spark for “citizen developers” who want to run their Spark logic without needing to have a deep understanding of Spark itself. This concept works great until it doesn’t. When it stops working, it can lead to support cases that last for months or years. At that point the “citizen developer” may regret using a tool that they never really understood in the first place! Hiding the Yarn dependency of Spark from a “citizen developer” may do more harm than good.
Spark Executors:
Spark executors are pretty important in Synapse – just as they are important in every other Spark environment. When an executor has persistent data (whether in RAM or localCheckpoint or somewhere else) then you don’t want the executor to suddenly be killed. It may lead to repeating a lot of costly computation, or network traffic. It may even lead to the death of the outer Spark batch.
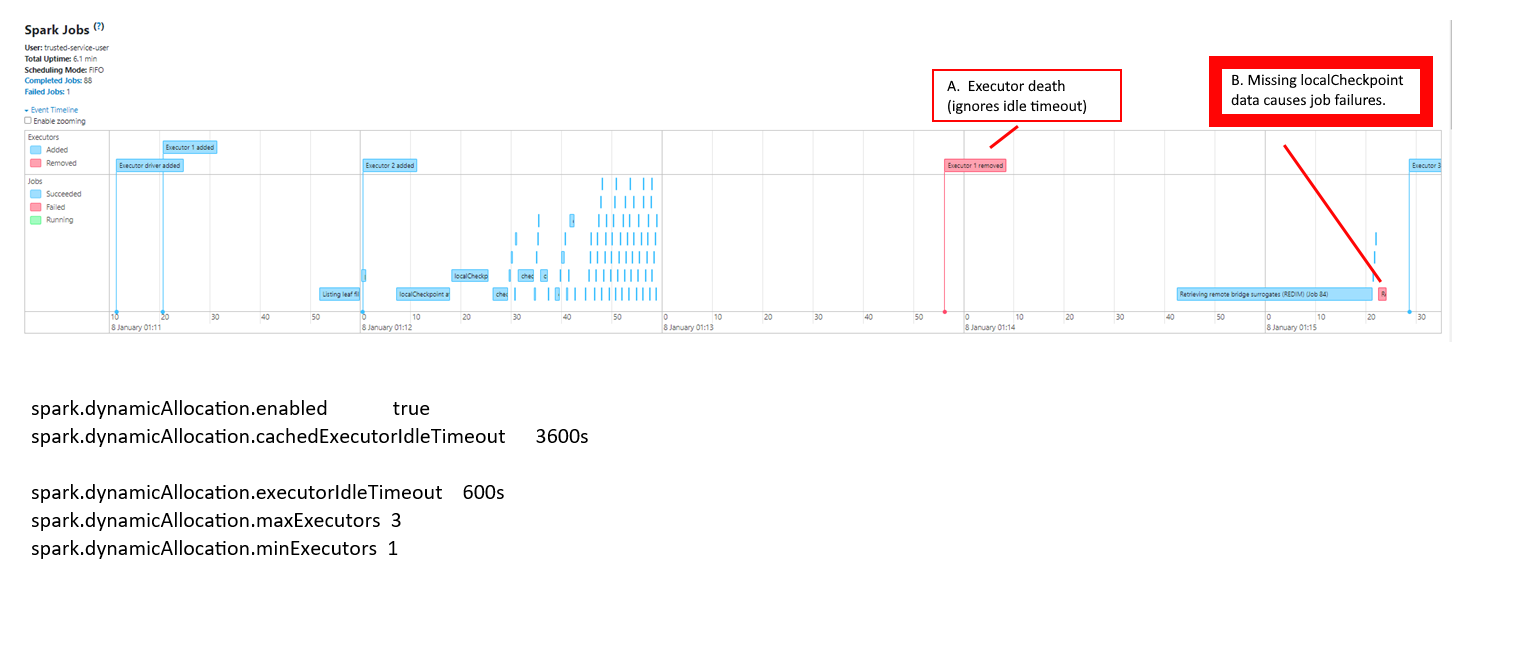
I encountered a problem in Microsoft Synapse recently where executors were being suddenly killed, and violating the Spark preferences that are specifically intended to keep them running. There are “dynamic allocation” properties like “spark.dynamicAllocation.executorIdleTimeout” that can be used to inform Spark not to kill an executor for a period of time. Yet in Synapse Analytics I discovered that my executors were occasionally being killed within seconds of being started! (And this would lead to even bigger problems because they had participated in critical dataframe operations like “localCheckpoint()”)
The unexpected termination of the executors can be confirmed by some of the logged messages in the Spark driver (stderr). But I was not able to explain WHY the executors were dying, based on what is visible to the customer in the monitoring blade or in the Spark UI. There was no recourse but to open a multi-month support ticket with CSS.
I’ve have endless problems with networking bugs in Synapse, so my initial suspicion was that this was yet another case of some unexpected socket exception that was encountered by a internal component of the Microsoft Synapse platform.
Below is an image of the Spark UI showing the sudden death of an executor after three minutes, despite the idle timeout of ten minutes.
Logs:
The logging in the stderr log of the driver makes it very clear that the Yarn resource manager was killing a host:
“received decommission host message for vm-c2972144.”
And the Spark platform made it very clear that the removal of the related executors was unexpected:
2023-00-00 01:02:03,021 INFO ExecutorMonitor [spark-listener-group-executorManagement]:
Executor 1 is removed. Remove reason statistics: (gracefully decommissioned: 0, decommision unfinished: 0,
driver killed: 0, unexpectedly exited: 1).
2023-00-00 01:02:04,040 INFO KustoHandler [spark-listener-group-shared]:
Logging ExecutorError with appId: application_1701648212345_0060 to Kusto:
Map(_source -> system, _jobGroupId -> , _detail -> None, _executionId -> -1, _level -> error, _helpLink -> ,
_description -> ExecutorUnknownReason is an error for which is not classified and/or don't know what it is.
Best steps is to look at driver and executor logs alongside any additional logging steps such as
setting trace level to sparkContext.setTraceLevel("ALL") If problem not solved, contact Synapse/Trident support.,
_name -> Spark_System_Executor_ExecutorUnknownReason,
_executorId -> 1)
… given this evidence, I was pretty certain that the Synapse PG would acknowledge a bug and fix it.
Blame:
However in the end they blamed these issues on the Yarn service which is totally obscured from the customer. It seems contradictory to hide the existence of Yarn from a Synapse customer, but then put the blame on Yarn when something goes wrong. The final explanation is that there is some sort of incompatibility between the “auto scale” implementation for Yarn, and the dynamic allocation properties for Spark. If you enable auto-scaling of a Yarn cluster, then your Spark executors are susceptible to being suddenly killed.
There are multiple contradictions going on here. First of all, customers who are subject to these types of Yarn-related problems should have *visibility* to investigate Yarn.
It turns out that even Mindtree/CSS has no direct visibility to troubleshoot Yarn any more than a customer does, so even the support engineer is forced to relay these problems all the way back to the Microsoft PG and wait for them to provide an explanation.
Microsoft gives no surface area to influence Yarn behavior. This is because Synapse is supposed to be “easy” and because Yarn only exists for the sake of hosting Spark itself. Given the design, it should become the responsibility of Microsoft to prevent customers from submitting dynamic-allocation workloads that are invalid and have preferences that will be *ignored* by Yarn (eg. the property spark.dynamicAllocation.executorIdleTimeout will not be respected). It is Microsoft’s job to resolve the friction between Spark application and the back-end Yarn service. If they can’t resolve this friction on their own, they should immediately alert the customer of the incompatibility, rather than starting jobs that are destined to fail in a strange way.
In the closing statements of this case, Microsoft essentially states that Synapse’s “auto scale” and Spark’s “dynamic allocation” are not compatible with each other. They say that the incompatibilities exist in the OSS Apache Spark project as well. This was an eye-opener, given that “auto scale” and “dynamic allocation” are both extremely popular features of Spark clusters, and there is almost no discussion in the OSS community about the incompatibilities. They pointed me to some obscure Jira issues like this one which indicates that Yarn and spark don’t always play very well together: https://issues.apache.org/jira/browse/SPARK-39024
Workaround:
The best workaround is probably to disable “auto scale” for any clusters where we rely on “dynamic allocation” for executors (especially executors that use locally-persistent data).
This was a hard lesson to learn and all that much harder on a platform like Synapse where there is no surface area to troubleshoot the Yarn side of the equation.
It is at times like these when a customer must decide whether they are ready to graduate from an “easy” Spark platform to a more mature one that is oriented towards software engineers. I’m becoming increasingly frustrated by the “easy” varieties of Spark (as found in Synapse or Fabric or ADF.) A common problem that I’ve found with these “easy” Spark implementations is related to support, and it is not obvious until after a customer has tried opening a support ticket or two. Customers will then discover that the Mindtree/CSS engineers who receive your cases are only expecting to receive “easy” ones (from “citizen developers”). Any problem that is complex will lead to a very frustrating support experience. (You are better off to recreate a complex Spark problem on a different Spark platform like Databricks or HDInsight, since the expertise and experience of your support engineer will allow you to get to the finish line all that much faster. Better yet, you should run OSS Spark for yourself and use it as a baseline for comparisons against Synapse.)